
Z produktu do reklamy
Po kilku miesiącach pracy nad produktem — w Znanym Lekarzu — nabierałem przekonania, że taki klimat i środowisko mi odpowiada. Wyrobiłem sobie również zdanie, że w branży reklamowej ciężko spotkać dobrych specjalistów (w IT) i zastanawiałem się, dlaczego ktoś miałby dla siebie wybrać taką ścieżkę kariery. Nawet kiedyś zarzekałem się, że nigdy „do branży” nie wrócę.
Zmieniłem zdanie. Zdecydowałem, że warto sobie dać jeszcze jedną szansę, ale tym razem w lepszym otoczeniu, z ciekawszymi ludźmi, większymi klientami — może po prostu nie potrafiłem dobrze ocenić pracy w reklamie, bo widziałem tylko jej mały wycinek, a w dodatku z nienajlepszej strony. Nawet pomimo faktu, że miałem chyba najmniej związane z kodem zadania spośród programistów DocPlannera, to i tak brakowało mi tego dreszczyku emocji, problemów związanych z ludźmi, a nie z kodem.
Przez pierwsze tygodnie po odejściu z poprzedniej roboty zacząłem sobie przypominać wszystkie dobre rzeczy, które tak chwaliłem we wczesnych dniach w Znanym Lekarzu, a które teraz zostawiłem za sobą — zgrany zespół, świetna wizja produktu, sprytni ludzie, wspólny cel, dbanie o kulturę pracy, etc. Stało się jasne, że to właśnie tych wartości muszę szukać w nowym miejscu, bez względu na typ projektów, które będą tam realizowane.
Miłego „cięcia wordpressów”
I znalazłem. Gdzieś w okolicach lutego trafiłem do Ars Thanea. I wszystko pasowało. Firma akurat była w trakcie większych zmian w IT. Mieliśmy stanąć przed wyborem nowego frameworka i CMS-a, wprowadzić wyższą jakość kodu i zbudować zestaw dobrych praktyk. Pomimo pracy „na kliencie”, z deadline’ami za pasem, filarem programistów miało być właśnie solidne podejście do kodu, bez chodzenia na skróty. Największym problemem zdawała się sprawna komunikacja z innymi zespołami w firmie.
I wtedy wchodzę ja, ubrany cały na biało… A tak na serio, to właśnie zgodnie z tą wizją trafiłem do zespołu — budowanie dobrych praktyk, wdrożenie nowoczesnego frameworka i zbudowanie platformy dla głównego klienta, która miała być obsługiwana przez najbliższe kilka lat. Byłem nastawiony naprawdę pozytywnie do nadchodzących wyzwań. Oczywiście nie każdy podzielał moje odczucia — kiedy podzieliłem się moją decyzją ze znajomymi, jeden z nich pogardliwie życzył mi „miłego cięcia wordpressów”.
Teraz, po roku, można spojrzeć wstecz i zobaczyć ile udało nam się osiągnąć i jak zmienił się krajobraz po bitwie. A naprawdę było nad czym pracować:
- Oczywiście sam kod i podejście do niego. Panowało „agencyjne” podejście, w którym cel uświęcał środki i nie było nawet pomysłu na realizację dobrych praktyk kodowania. Używany framework i istniejący kod nie pomagały. Wręcz naturalnym było kopiowanie poprzednio używanych modułów, nawet bez głębszego zrozumienia co i dlaczego w taki sposób robią.
- Zespół, głównie sami programiści. Z jednej strony praca w takim trybie „zepsuła” ludzi, tłumiąc ich oczekiwania, że coś może się zmienić na lepsze; z drugiej strony nikt nie myślał o tym nowym celu podejmując z nimi współpracę. Liczyła się krótkoterminowa efektywność.
- Sposób pracy, komunikacja. To w zasadzie nieodkryte terytorium. Pokój client service był na innym piętrze i wciąż panowała atmosfera typu „my” vs „oni”. Panujące procedury sprawiały wrażenie spisanych na kolanie i nie tworzących spójnej całości.
- Używane narzędzia, zarówno do prowadzenia projektów jak i do budowania aplikacji. Główne narzędzie do ticketowania było wyjęte z głębokich odmętów poprzedniej dekady. Narzędzia wspierające programistów praktycznie nie istniały.
Jeszcze zanim zaczęliśmy na dobre wprowadzać zmiany, miałem okazję odczuć negatywne efekty zastanej sytuacji. Mój pierwszy większy projekt poszedł tak źle, że zacząłem wątpić w swoje umiejętności i powoli zastanawiałem się, czy czasem nie popełniłem sporego błędu, decydując się na współpracę. Na szczęście dla mnie okazało się, że nie jestem taki całkiem do kitu i jak tylko pozbyłem się wszystkiego dookoła, co przeszkadzało nam bardziej, niż pomagało — praca poszła sprawnie.
Budowanie platformy
Po ciężkich przeprawach z pierwszych kilku tygodni zaczęło się pojawiać światełko w tunelu. Przed nami stanął wybór frameworka i CMS-a, na którym będziemy pracować przez najbliższe lata i który pozwoli nam się wyrwać z programistycznego średniowiecza. Równolegle zaczęliśmy się zastanawiać w jaki sposób usprawnić pracę i polepszyć komunikację.
Framework
To było trochę oczywiste już od mojej pierwszej rozmowy z Ars Thanea, ale teraz dopiero stało się rzeczywistością — Symfony 2 miało być naszymi fundamentami. Nie tylko sam framework, ale również wartości z nim związane. Posiadając podstawę, która nas nie ogranicza, mieliśmy cel podążania za takimi ideałami jak SOLID, reusability, oddzielanie kodu od konfiguracji, ale również lepszym projektowaniem architektury aplikacji, aby elementy o podobnym celu biznesowym były realizowane tymi samymi ścieżkami w kodzie, unikając copypasty i dziesiątek różnych wersji tej samej funkcjonalności.
To był dość prosty wybór. Można nawet powiedzieć, że community zrobiło to za nas. Trudniejsza część stała wciąż przed nami — CMS. Dla mnie to było szczególne wyzwanie — nie dość, że był to pierwszy projekt, który musiałem postawić od zera na Symfony (nie uczestniczyłem przy tworzeniu wstępnej architektury na Symfony w Znanym Lekarzu, a i po wdrożeniu nie angażowałem się za bardzo), to również nigdy nie stawiałem komercyjnego CMS-a (nie wydaje mi się, żebym nawet konfigurował coś pokroju WordPressa), nie mówiąc nawet o projekcie tej skali. Nie byłem więc w stanie opierać się na doświadczeniu, pozostała mi intuicja i szybki research.
Metodę ostatecznego wyboru można podzielić na trzy etapy:
- Użyjmy sprawdzonych standardów. Pod młotek poszło Symfony CMF oraz Sonata Admin. Okazuje się, że był to strzał kulą w płot. Nie było tam praktycznie żadnych gotowych rozwiązań, które moglibyśmy użyć. Szukaliśmy czegoś o poziom wyżej — narzędzia do budowania strony, a nie dopiero CMS-a, na którym później będzie można oprzeć tę stronę.
- Skoro nie istnieje gotowiec, to może napiszmy własnego CMS-a. Zaczęły pojawiać się takie głosy, ale od razu było wiadomo, że nie jest to dobry pomysł. Nie ten czas i nie ta skala, żeby zamiast budować stronę klienta, skupiać się na tworzeniu własnego produktu. Fakt, że zostało nam mniej więcej sześć tygodni do przedstawienia wstępnej wersji serwisu, skutecznie zamknął ten temat.
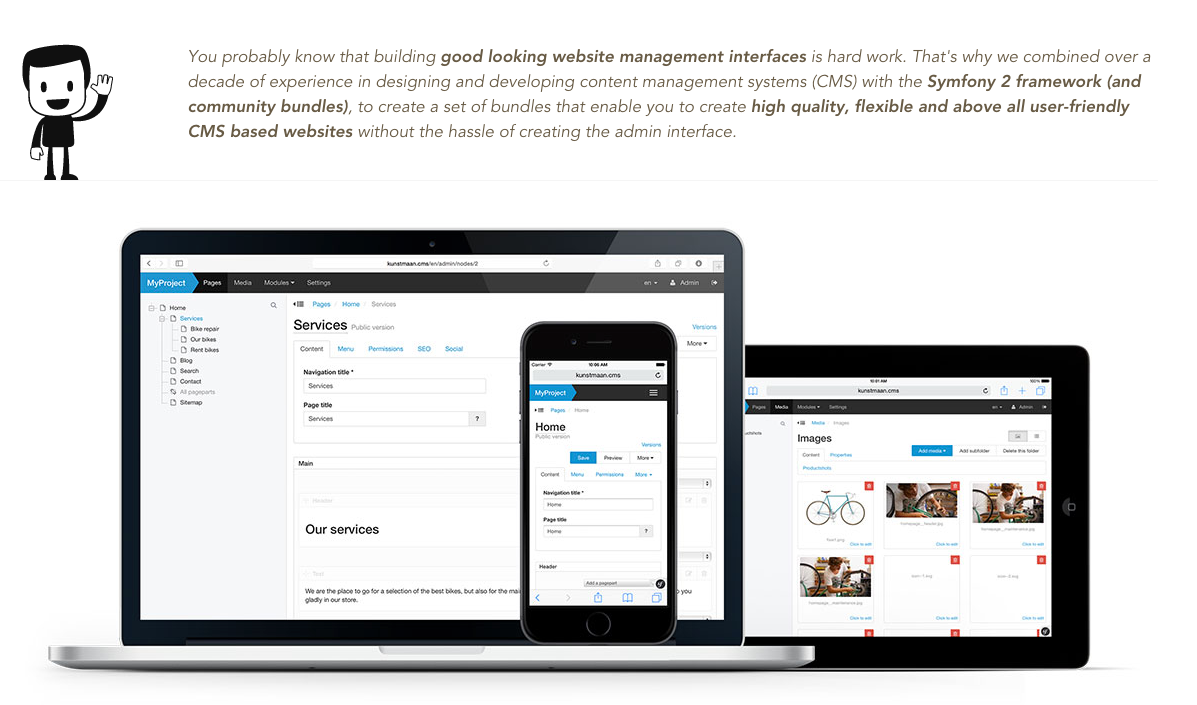
- Poszukajmy CMS-ów opartych o Symfony. Mieliśmy tu czterech, może pięciu kandydatów. Szybko trafiliśmy na ten o śmiesznie brzmiącej nazwie: Kunstmaan. Masa gotowej funkcjonalności, która w porównaniu do przejść z Presta / CMF / Sonatą po prostu działała po wyjęciu z pudełka. Oparcie o Symfony gwarantowało, że — prościej lub trudniej — będzie można modyfikować tę aplikację we własnym zakresie. Dokumentacja, przykłady i generatory pozwoliły nam wystartować z kopyta.
W pierwszej połowie maja zaczęliśmy budować platformę opartą o Kunstmaan Bundles CMS — decyzja, która ukierunkowała większość pozostałych zmian, które udało nam się wprowadzić do dziś.
Prowadzenie projektów
Jeśli miałbym wartościować, to drugą najważniejszą zmianą było stworzenie teamów projektowych. Przestaliśmy myśleć w kategoriach pokoi, stanowisk i rozbieżnych celów; w to miejsce zaczęło się pojawiać: ludzie, zespół, termin, efekt. Przeprowadziliśmy eksperyment i zebraliśmy w jednym miejscu cały team projektowy: od grafików, przez client service, project management po programistów — backend oraz frontend.
Jak ręką odjął naprawiliśmy tym połowę problemów z komunikacją. Po pierwsze wszelkie wątpliwości można było rozwiązać na miejscu. Nie trzeba było pisać maili, komentarzy ani wybierać się na spacer na niższe piętro; wystarczyło się obrócić. Druga sprawa to efekt czysto ludzki. Zniknęła niepisana bariera, która do tej pory utrzymywała się pomiędzy działami. Widząc na co dzień pracę całego zespołu, każdy nabierał do niej dystansu i zaczął rozumieć niedociągnięcia. Przykładowo:
- Programiści przestali narzekać na project management za brak materiałów widząc, jak wygląda proces współpracy z klientem i od samego początku mogli rozumieć funkcjonalności z biznesowego punktu widzenia, co dawało szerszy kontekst przy podejmowaniu decyzji.
- Frontendowcy przestali mieć wymówki typu „ach ci graficy” mając ich obok siebie i mogąc uczestniczyć w projekcie na wczesnym etapie projektowaniu
Równolegle w firmie pojawiła się Jira i Confluence, zastępując przerdzewiały system ticketowy, który jakimś sposobem uchował się do 2015 roku. W oparciu o te narzędzia zaczęliśmy wprowadzać agile’owe praktyki, które miały na celu po prostu usprawnienie ogólnej wymiany informacji:
- Kickoffy (lub planowanie) w tygodniowych lub dwutygodniowych cyklach. Długie, poniedziałkowe spotkania, w których brał udział cały zespół, miały na celu przełożenie narysowanych widoków na konkretne zasady i funkcjonalności. Był to moment na dogadanie szczegółów i wyjaśnienie spornych kwestii.
- W ramach IT pojawiło się szacowanie czasu poszczególnych tasków
- Codziennie rano o 10.05 odbywał się szybki status, żeby każdy był na bieżąco z projektem. To taka ostatnia okazja, żeby reagować, jeśli coś działo się nie tak — brakowało materiałów, zadania się przeciągały, czyjaś interwencja była komuś potrzebna, etc.
Mówiąc krótko, eksperyment się udał. Nie było idealnie. Szacowanie pracy przez zespół przed wyznaczeniem deadline’u nie wychodzi nam do dzisiaj. Próba zamykania tasków w sprinty jest zupełnie nieadekwatna do naszego trybu pracy. Statusy, zamiast trwać 5 minut potrafią się zamieniać w długie dyskusje na temat wyższości foobara nad eglebegle. Jednak ogólny wydźwięk jest jasny — praca w teamie projektowym i dobra komunikacja daje efekty. Od tej pory naturalne jest, żeby przed startem projektu zebrać i posadzić koło siebie wszystkie zaangażowane osoby.
Ludzie
Nie przypominam sobie, żeby w poprzednim układzie ktoś interesował się cudzym kodem. Wymiana wiedzy pomiędzy programistami polegała głównie na wytłumaczeniu jak działa lub gdzie zaimplementowana jest dana logika biznesowa. Jedną z wartości, którą przyniosło ze sobą Symfony, było uwspólnienie kodu. Z jednej strony przez proste coding standard, ale z drugiej strony — każdy kawałek kodu miał być pisany w taki sposób, aby nie można było odróżnić, które z nas go stworzyło.
Głównym motorem napędowym tej zmiany było przejście na GitHuba i używanie Pull Requestów. Zaczęliśmy kolektywnie dbać o to, co trafia do repozytorium aplikacji. To doskonała metoda na wymianę wiedzy nie tylko o samej aplikacji, ale też o dobrych praktykach, doświadczeniach zdobytych na innych projektach, lepszych rozwiązaniach technologicznych, kruczkach i pułapkach, w które się nieświadomie wpędzamy.
Od mojego startu wymienił się też praktycznie cały zespół IT. Teraz każda osoba wie od pierwszego dnia, jak wyglądają nasze wartości i do czego dążymy. Nawet jeśli komuś brakuje umiejętności, to wie, że musi próbować równać w górę i nie ma wymówek do pisania kodu, który nie spełnia naszych standardów.
Rozwój miękkich umiejętności
Team IT to nie tylko programowanie. Stawiamy równie silny nacisk na sprawne kodowanie co na umiejętności miękkie. Wśród kilkunastu wartości, które sobie wspólnie w teamie określiliśmy, nie więcej jak trzy są związane z wiedzą techniczną; pozostałe dotyczą takich elementów jak dobra komunikacja, szczery feedback, odpowiedzialność i profesjonalizm, biznesowe nastawienie, etc.
Wycofanie się z szufladkowania programistów jako robotów, które bezmyślnie wykonują zadania im powierzone spowodowało, że każdy z nas jest bardziej zaangażowany w realizowane projekty. A to jeszcze bardziej pogłębia pozytywne relacje z innymi działami. Wcześniej, będąc pragmatycznym, client service musiało operować gotowymi rozwiązaniami w rozmowach z działem IT. Teraz dziewczyny się przekonały, że już nie muszą tak robić — mogą przedstawić problem i liczyć na propozycję efektywnego rozwiązania ze strony programisty. Zniknęły również „nie da się” na rzecz wyjaśnienia sytuacji i propozycji alternatyw.
Cały czas trwa praca nad dostosowaniem naszego języka do odbiorcy. Nie tylko musimy starać się unikać żargonu i tłumaczyć — nieraz skomplikowane tematy — w sposób zrozumiały dla laików, ale też uczymy się brać pod uwagę charakter rozmówcy i prowadzić dyskusję w adekwatny dla niego sposób. Już niedługo zrealizujemy kolejny krok w tym kierunku — będę prowadził szkolenie oparte o ideę energii w modelu Insights Discovery.
Używanie gotowych narzędzi
Z jednej strony panował trochę syndrom „not invented here”, z drugiej strach przed używaniem gotowych narzędzi. Z trzeciej może trochę ambicja poprawy świata? W każdym razie domyślnym rozwiązaniem każdego problemu było… Stworzenie narzędzia. Długo starałem się z tym podejściem walczyć, ale mam wrażenie, że wywalczyłem. Pomijając już samo używanie istniejących bibliotek, które teraz jest super proste dzięki composerowi i dość dobrze rozwiniętemu community, udało mi się wprowadzić przekonanie, że lepiej dostosować się do gotowego, płatnego narzędzia, niż borykać się z własną implementacją.
Kluczowym chyba przykładem na to było użycie Algolii. Z początku ciężko było mi wytłumaczyć w teorii, dlaczego potrzebujemy najpierw zaimplementować integrację, a potem jeszcze płacić za usługę, która wydawała się tym samym co darmowy i wbudowany już w CMS-a ElasticSearch. Dopiero po stworzeniu PoC i porównaniu efektów wybór stał się jasny.
Przez ostatnie miesiące sukcesywnie dokładaliśmy „gotowce” do naszego stacku, który obecnie zawiera między innymi:
- Symfony wraz z popularnymi bundlami, takimi jak
FOSUser,HWIOAuth,KnpSnappy,JMSSerializer,FOSOAuthServer… - GitHub
- Wercker — środowisko continuous integration
- Sentry — monitorowanie błędów aplikacji
- Uploadcare - obsługa wgrywania plików
- Heroku
- Google Tag Manager — zarządzanie osadzaniem kodów analitycznych na stronach
- Cronitor — monitoring tasków ustawionych w cronie
- Zapier — hydraulika łącząca ze sobą wiele usług
- Loader.io — testy obciążeniowe
- Wspomniana wcześniej Algolia — realtime search
- GhostInspector — testy integracyjne (można powiedzieć, że to Selenium as a Service)
- Pusher — komunikacja w realtime po websocketach
- Postmark oraz Amazon SES — wysyłka maili
- Cloudflare — content delivery
Deployment
Na specjalną wzmiankę zasługuje deployment. Przeskoczyliśmy z wrzucania wybranych plików ręcznie na serwery produkcyjny, testowy czy Q&A na pełną automatyzację. Do tego celu używaliśmy lub używamy wciąż takich narzędzi jak:
- Amazon AWS + OpsWorks
- Amazon Beanstalk
- Heroku
- Wercker (continuous integration and deployment)
- Docker
Przede wszystkim, zgodnie z How to deploy software, proces deploymentu stał się prosty, automatyczny i zawsze taki sam. Nikt z nas nie musi się zastanawiać w jaki sposób go wykonać, które pliki może przerzucić, jakie polecenia powinien wykonać przed lub po deploymencie. Nawet wewnętrzne narzędzia, odpalone na developerskich serwerach mają przygotowane skrypty, które w idioto-odporny sposób są w stanie uruchomić nową wersję aplikacji.
To jeden z etapów przystosowywania aplikacji do metodologii twelve-factor app. Podążanie za tymi zasadami pozwoliło nam pozbyć się czegoś, co dla mnie jest niewyobrażalne, a panowało tu wcześniej nagminnie — zmian „na żywo” na produkcji, które nie mają odzwierciedlenia w repozytorium.
Taka architektura upraszcza również development.
- Po pierwsze konfiguracja polega wyłącznie na podaniu zmiennych konfiguracyjnych, zawsze w ten sam sposób, lub użycie domyślnych wartości. Nie ma skomplikowanych plików konfiguracyjnych, które trzeba kopiować z wersji
i ręcznie dostosowywać. - Po drugie zautomatyzowany deployment to częsty deployment. Nie ma strachu przed wrzucaniem tygodnia zmian na produkcję w jednym rzucie. Nie ma zmian innych developerów „wiszących” na środowisku stage. Wszystko, co trafia na
mastera, trafia zaraz na produkcję - Po trzecie automatyzacja to bezpieczeństwo — brak czynnika ludzkiego, brak procedur, za którymi trzeba podążać oraz możliwość wpięcia zabezpieczeń, jak np. testów jednostkowych przed deploymentem i testów integracyjnych po deploymencie.
- Po czwarte deployment jednym poleceniem to łatwy deployment dowolnej wersji aplikacji w dowolne miejsce — dlatego mamy środowisko Q&A, na którym możemy uruchomić dowolną wersję aplikacji (czytaj: brancha) w wyizolowanym środowisku — wszystko przy pomocy jednego guzika.
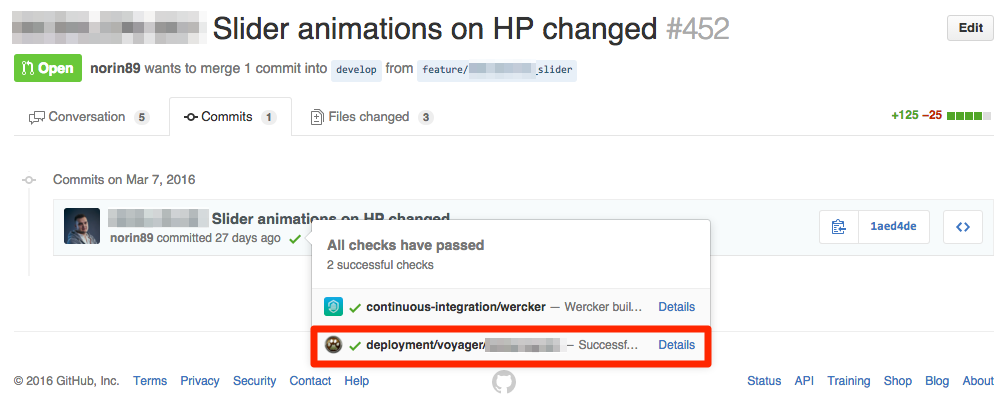
Najdalej posuniętą automatyzacją jest oczywiście Heroku, gdzie build, testy, konfiguracja i deployment wpięte są już na poziomie pushowania commitów. Jest jeszcze trochę do roboty w tym temacie, ale i tak jest już nieporównywalnie lepiej względem tego, co zastałem rok temu. Następnym krokiem może być np. wdrożenie runnable.
Spójność środowisk
Trochę w powiązaniu z deploymentem, staramy się utrzymywać dev-prod parity. Docker wydaje się idealnym narzędziem do tego, ale z przyczyn od nas niezależnych nie używamy go na produkcji. Na lokalnych środowiskach też docker się nie sprawdził ze względu na skomplikowany proces instalacji na osx (czekam mocno na Docker for Mac), więc pozostają środowiska testowe oraz Q&A.
Mamy za to wszędzie szyfrowane połączenia:
- Na produkcji jest to naturalnie komercyjny certyfikat SSL
- Na Q&A używamy Let’s Encrypt — systemu darmowych certyfikatów, który ma na celu upowszechnienie używania szyfrowanych połączeń
- Na lokalnych komputerach certyfikaty mamy generowane automatycznie przy pomocy nassau-https-proxy
Na load balancerze środowiska Q&A przekierowujemy -known/acme-challenge na /data/www, dzięki temu działa nam autoryzacja letsencrypt typu webroot:
https://gist.github.com/mlebkowski/48f1d18fc66b746be299305ea2dde3c0
#!/bin/bash
set -ueo pipefail
TLS_HOME=${TLS_HOME:-"/etc/letsencrypt"}
NGINX_CERTS=${NGINX_CERTS:-"/home/puck/dotfiles/nginx/certs"}
cert_expires() {
declare cert=$1
! openssl x509 -in "$cert" -noout -checkend 604800
}
renew_domain() {
declare domain=$1
local domain_tls="$TLS_HOME/live/$domain"
local cert="$domain_tls/fullchain.pem"
local key="$domain_tls/privkey.pem"
if [ ! -f "$cert" ] || cert_expires "$cert"; then
letsencrypt certonly --renew-by-default --webroot --webroot-path /data/www -d $domain
fi
cp "$cert" "$NGINX_CERTS/$domain.crt"
cp "$key" "$NGINX_CERTS/$domain.key"
}
main () {
local domains="$@"
if [ $# -eq 0 ]; then
domains=$(ls "$NGINX_CERTS/"*.crt | xargs -n 1 basename --suffix ".crt")
fi
for domain in $domains; do
renew_domain $domain;
done;
}
main "$@"
Testy automatyczne
Przy którymś z kolei refactorze byłem już przekonany, że potrzebujemy testera. Okazało się, że Humans Need Not Apply i nie ma takiej rzeczy, której nie może za nas wykonać robot. Tu do gry wchodzi GhostInspector. Maksymalnie prosty system do testów integracyjnych, wspomagany rozszerzeniem do przeglądarek, które pozwala „nagrywać” scenariusze testowe. W połączeniu z testami jednostkowymi w backendzie, automatycznie deployowanymi branchami (które w międzyczasie czekają na pull requeście na review) i środowiskiem CI/CD — możemy spać spokojnie, wiedząc że nasza zmiana nie popsuje nic na serwisie… A przynajmniej nic z kluczowych funkcjonalności.

W innych projektach zdecydowaliśmy się pójść o krok dalej i zastosować klasyczne TDD. Przejście z czerwonego testu, do implementacji, do zielonego testu. Ciężko mi nawet oszacować powstaniu ilu małych bugów to zapobiegło oraz ile czasu na ręczne testowanie czy debugowanie zaoszczędziło. Stosowanie testów integracyjnych w połączeniu z jednostkowymi daje gwarancję, że nie tylko każdy mały moduł działa jak należy, ale też połączone w jedną całość dają zamierzony efekt.
puck@marakei /V/D/____________.dev (develop)> phpunit -c app
PHPUnit 5.1.7 by Sebastian Bergmann and contributors.
............................I.............................SS... 63 / 63 (100%)
Time: 9.75 seconds, Memory: 65.50Mb
OK, but incomplete, skipped, or risky tests!
Tests: 63, Assertions: 130, Skipped: 2, Incomplete: 1.
puck@marakei /V/D/____________.dev (develop)>
Jakość kodu
Przykład tego ostatniego projektu idzie w parze z pisaniem bardzo doszlifowanego kodu. Połączenie takich wzorców jak single responsibility oraz inversion of control daje możliwość relatywnie łatwego testowania. Pomimo rozbicia na wiele miejsc kod staje się łatwiejszy do zrozumienia i utrzymania.
Kiedy zaczynałem uczyć się pisania testów jednostkowych, jednym z głównych problemów było testowanie metod prywatnych. Z czasem okazało się, że za każdym razem, kiedy pojawia się potrzeba przetestowania takiej metody, oznacza to prawdopodobnie, że powinno się ją zrefaktorować jako publiczną metodę nowej zależności danej klasy. I w taki sposób powoli ewoluuje nasz kod — większość prywatnych metod z czasem zamienia się na osobne serwisy, ukryte za interfejsami, wstrzyknięte przez kontener Symfony.
Prosty raport PhpMetrics może łatwo wskazać kandydatów do refactoringu:
Całość tworzy nam architekturę spójnego systemu, który jedną funkcjonalność realizuje zawsze w ten sam sposób, ale niekoniecznie zawsze tak samo, czyli np.: rejestracja zawsze wykonuje ten sam flow, ale użycie wzorca strategii czy event listenerów umożliwia wpływanie na poszczególne elementy tego procesu. W praktyce, zamiast kopiowania modułu na potrzeby jednej akcji, tworzymy bardziej elastyczną funkcjonalność i otwieramy drzwi do łatwiejszego (i tańszego!) wprowadzenia kolejnych modyfikacji w przyszłości.
Opublikowałem nawet bibliotekę nassau/registry-compiler, która pomaga zaimplementować architekturę używającą strategii:
https://gist.github.com/mlebkowski/1a89eb522e83775d340b3d96a8e01f23
#
# Convert this configuration value to a container parameter: %foobar.api_strategy%
#
foobar:
api_strategy: readonly
services:
foobar.api.strategy:
class: 'FoobarBundle\Service\Api\StrategyApiService'
public: false
arguments:
- '@foobar.api.strategy.collection'
calls:
- [ 'setStrategy', [ '%foobar.api_strategy%' ] ]
#
# See: https://github.com/mlebkowski/registry-compiler - automatically collect services using tags
#
foobar.api.strategy.collection:
class: 'Doctrine\Common\Collections\ArrayCollection'
public: false
tags:
- name: nassau.registry # magic!
tag: foobar.service.strategy_api_service
order: indexed
alias_field: strategy
class: 'FoobarBundle\Service\Api\ApiServiceInterface'
foobar.service.api_service.strategy.logger:
class: 'FoobarBundle\Service\Api\LoggingApiService'
public: false
arguments: [ "@foobar.service.api_service.backend", "@logger" ]
tags:
- name: foobar.service.strategy_api_service
strategy: default
fobar.service.api_service.strategy.readonly:
public: false
class: 'FoobarBundle\Service\Api\ReadOnlyApiService'
arguments: [ "@foobar.service.api_service.strategy.logger" ]
tags:
- name: foobar.service.strategy_api_service
strategy: readonly
foobar.service.api_service.backend:
class: 'FoobarBundle\Service\Api\BackendApiService'
public: false
arguments: [ "@foobar.api.sdk" ]
Dług technologiczny
Nigdy tak dobrze nie byłem w stanie wytłumaczyć zasady działania długu technologicznego, jak na naszym przykładzie. Oczywiście dług technologiczny jest rzeczą negatywną, ale również w dużej mierze nieuniknioną. Bardziej więc jest istotne umiejętnie nim zarządzać, niż za wszelką cenę unikać.
My byliśmy zmuszeni go zaciągnąć. Warunki biznesowe zmusiły nas do porzucenia części swoich zasad. I wszyscy widzieli co się dzieje, każdy miał świadomość tego, że ciężko nam się będzie wygrzebać z tej decyzji — ale była konieczna, aby zrealizować założenia projektu w terminie. Efektywnie zwiększyło to jego koszt, bo przez kolejne tygodnie i miesiące musieliśmy odkręcać spaghetti, które wpuściliśmy wtedy do kodu naszej aplikacji, a które potem sukcesywnie kąsało nas w najmniej oczekiwanych momentach.
Tak książkowy przykład otworzył nam oczy i pozwolił śledzić dług technologiczny w codziennej pracy. Wiemy, że każdy kawałek kodu, który trafia do repozytorium może się do niego przyczyniać, więc staramy się „w spokojnych czasach” pisać na tyle dobrze i wręcz pedantycznie, żeby w chwili „dokręcenia śruby” mieć pole do manewru — żeby można było zaciemniać ładny i przejrzysty kod, a nie ten, w którym i tak już mało kto jest w stanie się połapać.
Open source
To, z czego ja jestem bardzo dumny to aktywny udział w projektach open source. Tak oto staramy się „oddawać” coś do projektu, który pozwolił nam odnieść sukces, pisząc regularnie poprawki do Kunstmaana (ponad 25 pull requestów od naszego teamu). Z drugiej strony, nie pozostajemy bierni i publikujemy własne projekty na GitHubie.
Po roku
Rok temu w połowie marca rozpocząłem współpracę z Ars Thanea. Kilka tygodni później jeszcze męczyły mnie wątpliwości, czy to dobry kierunek. Teraz kiedy patrzę wstecz na jedynie wycinek tego, co udało nam się razem osiągnąć — efekty mówią same za siebie.
